This post should feature a continually updated feed of all Twitter tweets tagged as: #evaluation

Monitoring and Evaluation NEWS
A news service focusing on developments in monitoring and evaluation methods relevant to development programmes with social development objectives. Managed by Rick Davies, since 1997
This post should feature a continually updated feed of all Twitter tweets tagged as: #evaluation
Kenya Heard, Elisabeth O’Toole, Rohit Naimpally, Lindsey Bressler. J-PAL North America, April 2017. pdf copy here
INTRODUCTION
Randomized evaluations, also called randomized controlled trials (RCTs), have received increasing attention from practitioners, policymakers, and researchers due to their high credibility in estimating the causal impacts of programs and policies. In a randomized evaluation, a random selection of individuals from a sample pool is offered a program or service, while the remainder of the pool does not receive an offer to participate in the program or service. Random assignment ensures that, with a large enough sample size, the two groups (treatment and control) are similar on average before the start of the program. Since members of the groups do not differ systematically at the outset of the experiment, any difference that subsequently arises between the groups can be attributed to the intervention rather than to other factors.
Researchers, practitioners, and policymakers face many real-world challenges while designing and implementing randomized evaluations. Fortunately, several of these challenges can be addressed by designing a randomized evaluation that accommodates existing programs and addresses implementation challenges.
Program design challenges: Certain features of a program may present challenges to using a randomized evaluation design. This document showcases four of these program features and demonstrates how to alter the design of an evaluation to accommodate them.
• Resources exist to extend the program to everyone in the study area
• Program has strict eligibility criteria
• Program is an entitlement
• Sample size is small
Implementation challenges: There are a few challenges that may threaten a randomized evaluation when a program or policy is being implemented. This document features two implementation challenges and demonstrates how to design a randomized evaluation that mitigates threats and eliminates difficulties in the implementation phase of an evaluation.
• It is difficult for service providers to adhere to random assignment due to logistical or political reasons
• The control group finds out about the treatment, benefits from the treatment, or is harmed by the treatment
TABLE OF CONTENTS
INTRODUCTION ……………………………………………………………………….. 3
TABLE OF CONTENTS……………………………………………………………………. 4
PROGRAM DESIGN CHALLENGES ……………………………………………………………. 5
Challenge #1: Resources exist to extend the program to everyone in the study area…………… 5
Challenge #2: Program has strict eligibility criteria …………………………………… 9
Challenge #3: Program is an entitlement…………………………………………………12
Challenge #4: Sample size is small …………………………………………………….16
IMPLEMENTATION CHALLENGES……………………………………………………………..20
Challenge #5: It is difficult for service providers to adhere to random assignment due to logistical
or political reasons …………………………………………………………………20
Challenge #6: Control group finds out about the treatment, benefits from the treatment,
or is harmed by the treatment………………………………………………………….23
SUMMARY TABLE ……………………………………………………………………….27
GLOSSARY ……………………………………………………………………………28
REFERENCES ………………………………………………………………………….29
/p>
Emily Namey, R&E Search for Evidence http://researchforevidence.fhi360.org/author/enamey
“The first two posts in this series describe commonly used research sampling strategies and provide some guidance on how to choose from this range of sampling methods. Here we delve further into the sampling world and address sample sizes for qualitative research and evaluation projects. Specifically, we address the often-asked question: How many in-depth interviews/focus groups do I need to conduct for my study?
Within the qualitative literature (and community of practice), the concept of “saturation” – the point when incoming data produce little or no new information – is the well-accepted standard by which sample sizes for qualitative inquiry are determined (Guest et al. 2006; Guest and MacQueen 2008). There’s just one small problem with this: saturation, by definition, can be determined only during or after data analysis. And most of us need to justify our sample sizes (to funders, ethics committees, etc.) before collecting data!
Until relatively recently, researchers and evaluators had to rely on rules of thumb or their personal experiences to estimate how many qualitative data collection events they needed for a study; empirical data to support these sample sizes were virtually non-existent. This began to change a little over a decade ago. Morgan and colleagues (2002) decided to plot (and publish!) the number of new concepts identified in successive interviews across four datasets. They found that nearly no new concepts were found after 20 interviews. Extrapolating from their data, we see that the first five to six in-depth interviews produced the majority of new data, and approximately 80% to 92% of concepts were identified within the first 10 interviews.
Emily’s blog continues here http://researchforevidence.fhi360.org/riddle-me-this-how-many-interviews-or-focus-groups-are-enough
Dizekes, P. (2017). Better wisdom from crowds. MIT Office News. Retrieved from http://news.mit.edu/2017/algorithm-better-wisdom-crowds-0125 PDF copy pdf copy
Ross, E. (n.d.). How to find the right answer when the “wisdom of the crowd” fails. Nature News. https://doi.org/10.1038/nature.2017.21370
Prelec, D., Seung, H. S., & McCoy, J. (2017). A solution to the single-question crowd wisdom problem.Nature, 541(7638), 532–535. https://doi.org/10.1038/nature21054
Dizekes: The wisdom of crowds is not always perfect. but two scholars at MIT’s Sloan Neuroeconomics Lab, along with a colleague at Princeton University, have found a way to make it better. Their method, explained in a newly published paper, uses a technique the researchers call the “surprisingly popular” algorithm to better extract correct answers from large groups of people. As such, it could refine “wisdom of crowds” surveys, which are used in political and economic forecasting, as well as many other collective activities, from pricing artworks to grading scientific research proposals.
The new method is simple. For a given question, people are asked two things: What they think the right answer is, and what they think popular opinion will be. The variation between the two aggregate responses indicates the correct answer. [Ross: In most cases, the answers that exceeded expectations were the correct ones. Example: If Answer A was given by 70% but 80% expected it to be given and Answer B was given by 30% but only 20% expected it to be given then Answer B would be the “surprisingly popular” answer].
In situations where there is enough information in the crowd to determine the correct answer to a question, that answer will be the one [that] most outperforms expectations,” says paper co-author Drazen Prelec, a professor at the MIT Sloan School of Management as well as the Department of Economics and the Department of brain and Cognitive Sciences.
The paper is built on both theoretical and empirical work. The researchers first derived their result mathematically, then assessed how it works in practice, through surveys spanning a range of subjects, including U.S. state capitols, general knowledge, medical diagnoses by dermatologists, and art auction estimates.
Across all these areas, the researchers found that the “surprisingly popular” algorithm reduced errors by 21.3 percent compared to simple majority votes, and by 24.2 percent compared to basic confidence-weighted votes (where people express how confident they are in their answers). And it reduced errors by 22.2 percent compared to another kind of confidence weighted votes, those taking the answers with the highest average confidence levels”
But “… Prelec and Steyvers both caution that this algorithm won’t solve all of life’s hard problems. It only works on factual topics: people will have to figure out the answers to political and philosophical questions the old-fashioned way”
Rick Davies comment: This method could be useful in an evaluation context, especially where participatory methods were needed or potentially useful
Context: “This report represents a basis for integrating big data and data analytics in the monitoring and evaluation of development programmes. The report proposes a Call to Action, which hopes to inspire development agencies and particularly evaluators to collaborate with data scientists and analysts in the exploration and application of new data sources, methods, and technologies. Most of the applications of big data in international development do not currently focus directly on monitoring, and even less on evaluation. Instead they relate more to research, planning and operational use using big data. Many development agencies are still in the process of defining their policies on big data and it can be anticipated that applications to the monitoring and evaluation of development programmes will start to be incorporated more widely in the near future. This report includes examples and ways that big data, together with related information and communications technologies (ICTs) are already being used in programme monitoring, evaluation and learning. The data revolution has been underway for perhaps a decade now. One implication for international development is that new sources of real–time information about people are for the first time available and accessible. In 2015, in an unprecedented, inclusive and open process, 193 members states of the United Nations adopted, by consensus, the 2030 Agenda for sustainable development. The 17 Sustainable Development Goals (SDGs) contained in the 2030 Agenda constitute a transformative plan for people, planet, prosperity, partnerships and peace. All of these factors are creating a greater demand for new complexity–responsive evaluation designs that are flexible, cost effective and provide real–time information. At the same time, the rapid and exciting developments in the areas of new information technology (big data, information and communications technologies) are creating the expectation, that the capacity to collect and analyse larger and more complex kinds of data, is increasing. The report reviews the opportunities and challenges for M&E in this new, increasingly digital international development context. The SDGs are used to illustrate the need to rethink current approaches to M&E practices, which are no longer able to address the complexities of evaluation and interaction among the 17 Goals. This endeavour hopes to provide a framework for monitoring and evaluation practitioners in taking advantage of the data revolution to improve the design of their programmes and projects to support the achievement of the Sustainable Development Goals and the 2030 Agenda.”
Rick Davies comment: As well as my general interest in this paper, I have two particular interests in its contents. One is what it says about small (rather than big) data and how big data analysis techniques may be relevant to the analysis of small data sets. In my experience many development agencies have rather small data sets, which are often riddle with missing data points. The other is what the paper has to say about predictive analytics, a field of analysis (within data mining defined more widely) that I think has a lot of relevance to M&E of development programmes.
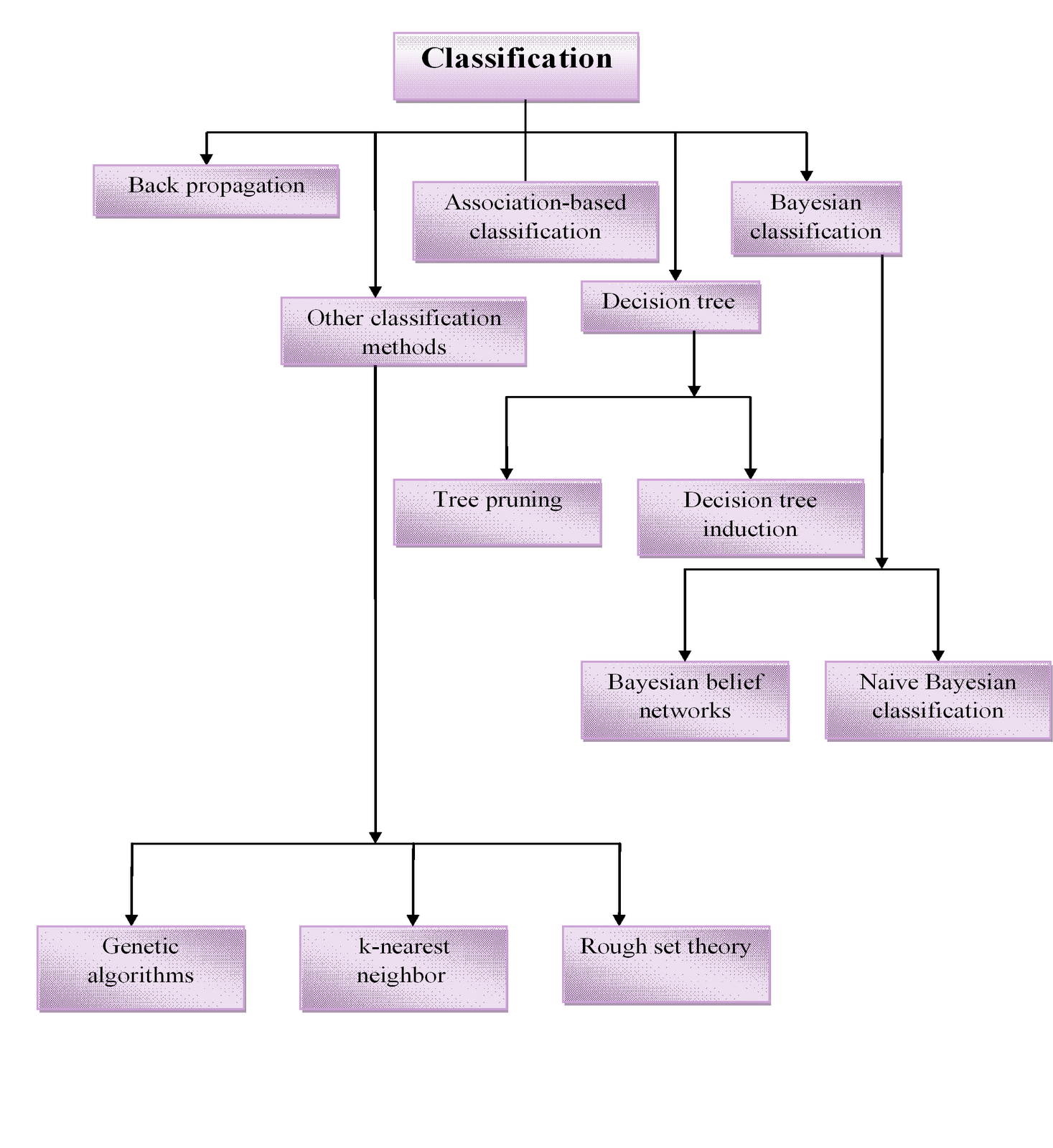
Re the references to predictive analytics, I was disappointed to see this explanation on page 48: “Predictive analytics (PA) uses patterns of associations among variables to predict future trends. The predictive models are usually based on Bayesian statistics and identify the probability distributions for different outcomes“. In my understanding Bayesian classification algorithms are only one of a number of predictive analytics tools which generate classifications (read predictive models). Here are some some classifications of the different algorithms that are available: (a) Example A, focused on classification algorithms – with some limitations, (b) Example B, looking at classification algorithms within the wider ambit of data mining methods, from Maimon and Rokach (2010; p.6) . Bamberger’s narrow definition is an unfortunate because there are simpler and more transparent methods available, such as Decision Trees, which would be easier for many evaluators to use and whose results could be more easily communicated to their clients.
Re my first interest re small data, I was more pleased to see this statement: “While some data analytics are based on the mining of very large data sets with very large numbers of cases and variables, it is also possible to apply many of the techniques such as predictive modelling with smaller data sets” This heightens the importance of clearly spelling out the different ways in which predictive analytics work can be done.
I was also agreeing with the follow on paragraph: “While predictive analytics are well developed, much less progress has been made on causal (attribution) analysis. Commercial predictive analytics tends to focus on what happened, or is predicted to happen (e.g. click rates on web sites), with much less attention to why outcomes change in response to variations in inputs (e.g. the wording or visual presentation of an on–line message). From the evaluation perspective, a limitation of predictive analysis is that it is not normally based on a theoretical framework, such as a theory of change, which explains the process through which outcomes are likely to be achieved. This is an area where there is great potential for collaboration between big data analytics and current impact evaluation methodologies” My approach to connecting these two types of analysis is explained on the EvalC3 website. This involves connecting cross-case analysis (using predictive analytics tools, for example) to within-case analysis (using process tracing or simpler tools, for example) through carefully thought though case selection and comparison strategies.
My interest and argument for focusing more on small data was reinforced when I saw this plausible and likely situation: “The limited access of many agencies to big data is another major consideration” (p69) – not a minor issue in a paper on the use and uses of big data! Though the paper does highlight the many and varied sources that are becoming increasingly available, and the risks and opportunities associated with their use.
Algorithms are means of processing data in ways that can aid our decision making. One of the weak areas of evaluation practice is guidance on data analysis, as distinct from data gathering. In the last year or so I have been searching for useful books on the subject of algorithms – what they are, how they work and the risks and opportunities associated with their use. Here are a couple of books I have found worth reading, plus some blog postings.
Books
Christian, B., & Griffiths, T. (2016). Algorithms To Live By: The Computer Science of Human Decisions. William Collins. An excellent over view of a wide range of types of algorithms and how they work. I have read this book twice and found a number of ideas within it that have been practically useful for me in my work
O’Neil, C. (2016). Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. New York: Crown Publishing Group. A more depressing book, but a necessary read nevertheless. Highlighting the risks posed to human welfare by poorly designed and or poorly used algorithms. One of the examples cited being labor/staff scheduling algorithms, which very effectively minimize labor costs for empowers, but at the cost of employees not being able to predictably schedule child care, second jobs or part time further education, thus in effect locking those people into membership of a low cost labor pool.Some algorithms are able to optimize multiple objectives e.g. labor costs and labor turnover (represented longer term costs), but both objectives are still employer focused. Another area of concern is customer segmentation, where algorithms fed on big data sets enable companies to differentially (and non-transparently) price products and services being sold to ever smaller segments of their consumer population. In the insurance market this can mean that instead of the whole population sharing the costs of health insurance risks, which may in real life fall more on some than others, those costs will now be imposed more specifically on those with the high risks (regardless of the origins of those risks, genetic, environmental or an unknown mix)
Ezrachi, A., & Stucke, M. E. (2016). Virtual Competition: The Promise and Perils of the Algorithm-Driven Economy. Cambridge, Massachusetts: Harvard University Press. This one is a more in-depth analysis than the one above, focusing on the implications for how our economies work, and can fail to work
Blog postings
Kleinberg, J., Ludwig, J., & Mullainathan, S. (2016, December 8). A Guide to Solving Social Problems with Machine Learning. Retrieved January 5, 2017, from Harvard Business Review website. A blog posting, easy to read and informative
Knight, Will, (2016, November 23) How to Fix Silicon Valley’s Sexist Algorithms, MIT Technology Review
Lipton, Zacharay Chase, (2016) The foundations of algorithmic bias. KD Nuggets
Nicholas Diakopoulos and Sorelle Friedler (2016, November 17) How to Hold Algorithms Accountable, MIT Technology Review. Algorithmic systems have a way of making mistakes or leading to undesired consequences. Here are five principles to help technologists deal with that.
“The foundations of algorithmic bias“, by Zacharay Chase Lipton, 2016. pdf copy here. Original source here
“This morning, millions of people woke up and impulsively checked Facebook. They were greeted immediately by content curated by Facebook’s newsfeed algorithms. To some degree, this news might have influenced their perceptions of the day’s news, the economy’s outlook, and the state of the election. Every year, millions of people apply for jobs. Increasingly, their success might lie, in part, in the hands of computer programs tasked with matching applications to job openings. And every year, roughly 12 million people are arrested. Throughout the criminal justice system, computer-generated risk-assessments are used to determine which arrestees should be set free. In all these situations, algorithms are tasked with making decisions.
Algorithmic decision-making mediates more and more of our interactions, influencing our social experiences, the news we see, our finances, and our career opportunities. We task computer programs with approving lines of credit, curating news, and filtering job applicants. Courts even deploy computerized algorithms to predict “risk of recidivism”, the probability that an individual relapses into criminal behavior. It seems likely that this trend will only accelerate as breakthroughs in artificial intelligence rapidly broadened the capabilities of software.
Turning decision-making over to algorithms naturally raises worries about our ability to assess and enforce the neutrality of these new decision makers. How can we be sure that the algorithmically curated news doesn’t have a political party bias or job listings don’t reflect a gender or racial bias? What other biases might our automated processes be exhibiting that that we wouldn’t even know to look for?”
Rick Davies Comment: This paper is well worth reading. It starts by explaining the basics (what an algorithm is and what machine learning is). Then it goes into detail about three sources of bias:(a) biased data, (c) bias by omission, and (c) surrogate objectives. It does not throw the baby out with the bathwater, i.e condemn the use of algorithms altogether because of some bad practices and weaknesses in their use and design
[TAKEAWAYS]
Many of the problems with bias in algorithms are similar to problems with bias in humans. Some articles suggest that we can detect our own biases and therefore correct for them, while for machine learning we cannot. But this seems far fetched. We have little idea how the brain works. And ample studies show that humans are flagrantly biased in college admissions, employment decisions, dating behavior, and more. Moreover, we typically detect biases in human behavior post hoc by evaluating human behavior, not through an a priori examination of the processes by which we think.
Perhaps the most salient difference between human and algorithmic bias may be that with human decisions, we expect bias. Take for example, the well documented racial biases among employers, less likely to call back workers with more more typically black names than those with white names but identical resumes. We detect these biases because we suspect that they exist and have decided that they are undesirable, and therefore vigilantly test for their existence.
As algorithmic decision making slowly moves from simple rule based systems towards more complex, human level decision making, it’s only reasonable to expect that these decisions are susceptible to bias.
Perhaps, by treating this bias as a property of the decision itself and not focusing overly on the algorithm that made it, we can bring to bear the same tools and institutions that have helped to strengthen ethics and equality in the workplace, college admissions etc. over the past century.
See also:
1. Punton, M., Vogel, I., & Lloyd, R. (2016, April). Reflections from a Realist Evaluation in Progress: Scaling Ladders and Stitching Theory. IDS. Available here
Interviews of stakeholders about if, how and why a program works, are a key resource in most REs (Punton et al). Respondents views are both sources of theories and sources of evidence for and against those theories, and there seems to be potential for mixing these up in way that the process of theory elicitation and testing becomes less explicit than it should be. Punton et al have partially addressed this by coding the status of views about reported outcomes as “observed”, anticipated” or “implied”. The same approach could be taken with recording of respondents’ views on the context and mechanisms involved.
Manzano makes a number of useful distinctions between RE and constructivist interview approaches. But one distinction that is made seems unrealistic, so to speak. “…data collected through qualitative interviews are not considered constructions. Data are instead considered “evidence for real phenomena and processes”. But respondents themselves, as shown in some quotes in the paper, will indicate that on some issues they are not sure, they have forgotten or they are guessing. What is real here is that respondents are themselves making their best efforts to construct some sense out of a situation.So the issue of careful coding of the status of respondents’ views, as to whether they are theories or not, and if observations, what status these have, is important.

Both papers had lots of useful advice on how to interview, from a RE perspective. This is primarily from a theory elicitation and clarification perspective.
Both papers noted difficulties in operationalising the idea of CMOs, but also had useful advice in this area. Manzano broke the concept of Context down into sub-constructs such as characteristics of the patients, staff and infrastructure, in the setting she was examining. Punton et al introduced a new category of Intervention, alongside Context and Mechanism. In a development aid context this makes a lot of sense to me. Both authors used interviewing methods that avoided any reference to “CMOs” as a technical term
After exploring what could be an endless variety of CMOs a RE process needs to enter a consolidation phase. Manzano points out: “In summary, this phase gives more detailed consideration to a smaller number of CMOs which belong to many families of CMOs”. Punton et al refers to a process of abstraction that leads to more general explanations “which encompass findings from across different respondents and country settings”. This process sounds very similar in principle to the process of minimization used in QCA, which uses a more algorithm based approach. To my surprise the Punton et al paper highlights differences between QCA and RE rather than potential synergies. A good point about their paper is that it explain this stage in more detail than that by Manzano, which is more focused specifically on interview processes.
The Punton et al paper does not go into this territory because of the early stage of the work that it is describing. Manzano makes more reference to this process, but mainly the context of interviews that are eliciting peoples theories. This is the territory where more light needs to be shone in future, hopefully by follow up papers by Punton et al. My continuing impression is that theory elicitation and testing are so bound up together that the process of testing is effectively not transparent and thus difficult to verify or replicate. But readers could point me to other papers where this view could be corrected…:-)
Against this background, this paper has been commissioned by DFID to answer two main questions:
1. What different methods and approaches can be used to estimate the value of evaluations before commissioning decisions are taken and what tools and approaches are available to assess the value of an already concluded evaluation?
2. How can these approaches be simplified and merged into a practical framework that can be applied and further developed by evaluation commissioners to make evidence-based decisions about whether and how to evaluate before commissioning and contracting?”
The paper proposes that:
While I agree with all of these…
.
.
{kind=link}
{kind=link}